写HTML是容易的, 但如果某部分出了问题而你找不到错误代码在哪里的时候, 这篇文章会介绍一些工具来帮助您.
| 先决条件: | 熟悉HTML , 例如已经阅读了 Getting started with HTML, HTML text fundamentals, 和 Creating hyperlinks. |
|---|---|
| 目标: | 学习基础使用调试工具查找HTML中的错误 . |
调试并不可怕
在编写某种代码时, 通常一切都是正常的, 直到你犯了某个错误那可怕的时刻便发生了, 你的代码无效了 — 无论这是不是你想要的. 例如下面,当我们想用compileRust语言去写一个简单的程序的时候,错误报告便会出现。
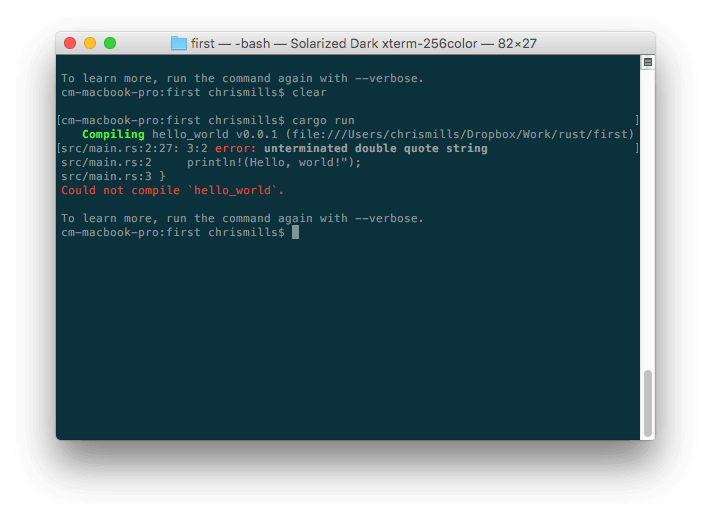 这里错误信息比较容易理解 — "双引号字符串未闭合". 如果你查看列表, 你大概会看到
这里错误信息比较容易理解 — "双引号字符串未闭合". 如果你查看列表, 你大概会看到(Hello, world!"); 这里缺少了一个双引号 ,然而当程序变庞大的时候错误信息也会变得更复杂和更难解释, 甚至上面这样简单的例子对于不了解Rust语言的人来说就会有点吓人。
调试没有那么可怕 — 编写和调试任何编程语言的关键是熟悉这门语言和工具。
HTML and 调试
HTML并不像Rust语言那么难以理解 — 在浏览器解析和显示它之前HTML不会被编译成其他形式 (这是解析而不是编译) HTML的element 语法可以说比“像Rust的”JavaScript 或 Python这样“真正的编程语言”更容易理解. 然而浏览器运行HTML比编程语言的运行更宽松,这可以说是好事也是坏事。
宽容模式代码
宽容的意思是什么呢? 通常当你写错代码的时候,你会遇到以下两种主要类型的错误:
- 语法错误: 由于拼写错误导致程序无法运行, 就像上面Rust的例子. 修正这些错误是没问题的,只要你熟悉正确的使用工具和知道错误信息的意思。
- 逻辑错误: 实际上语法是正确的,但代码不是你想要的,这意味着程序运行不正确. 逻辑错误通常比语法错误更难修复,因为没有一个错误信息指示你到错误的来源。
HTML本身不容易因语法错误出错,因为浏览器是以宽松模式来运行, 这意味着即使出现语法错误浏览器依然会运行。浏览器通常都有自己的规则来解析语法错误的标记语言,所以程序仍然会运行,尽管可能不是你预期的样子。这样当然仍然会地来问题。
Note: HTML is run permissively because when the Web was first created, it was decided that allowing people to get their content published was more important than making sure all the syntax was absolutely correct. The Web would probably not be as popular as it is today, if it had been more strict from the very beginning.
主动学习: 学习宽容式代码风格
It's time to study the permissive nature of HTML code for yourselves.
- First, get hold of a copy of our debug-example demo and save it somewhere locally. This is deliberately written to have some errors in it for us to explore (the HTML markup is said to be badly-formed, as opposed to well-formed.)
- Next, try opening it in a browser — you will see something like this:
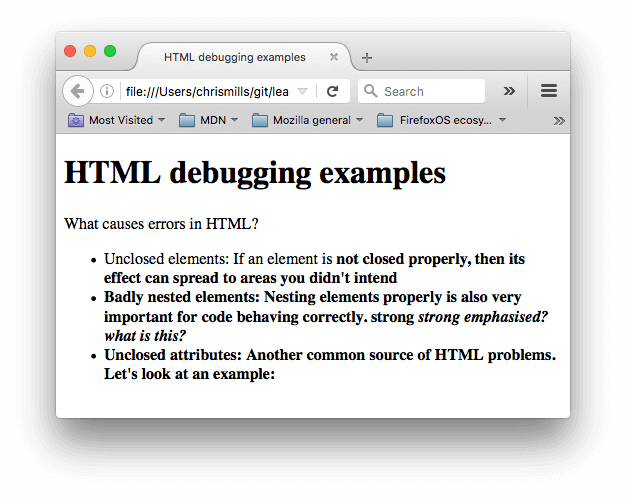
- This immediately doesn't look great; let's look at the source code to see if we can work out why (only the body contents are shown):
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - Let's review the problems we can see here:
- The paragraph and list item elements have no closing tags. Looking at the image above, this doesn't seem to have affected the markup rendering too badly, as it is easy to infer where one element should end, and another should begin.
- The first
<strong>element has no closing tag. This is a bit more problematic, as it isn't easy to tell where the element is supposed to end. In fact, the whole of the rest of the text looks to have been strongly emphasised. - This section is badly nested:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. It is not easy to tell how this has been interpreted, because of the previous problem. - The
hrefattribute value has a missing closing double quote. This seems to have caused the biggest problem — the link has not rendered at all.
- 现在我们看看浏览器渲染出来的标记语言,而不是源代码中的标记语言。我们打开浏览器的开发者工具。如果你对这个不太熟悉的话,先浏览一下Discover browser developer tools。
- 在开发者模式中的审查器件,你可以看到被渲染出来的标记语言会像这样。
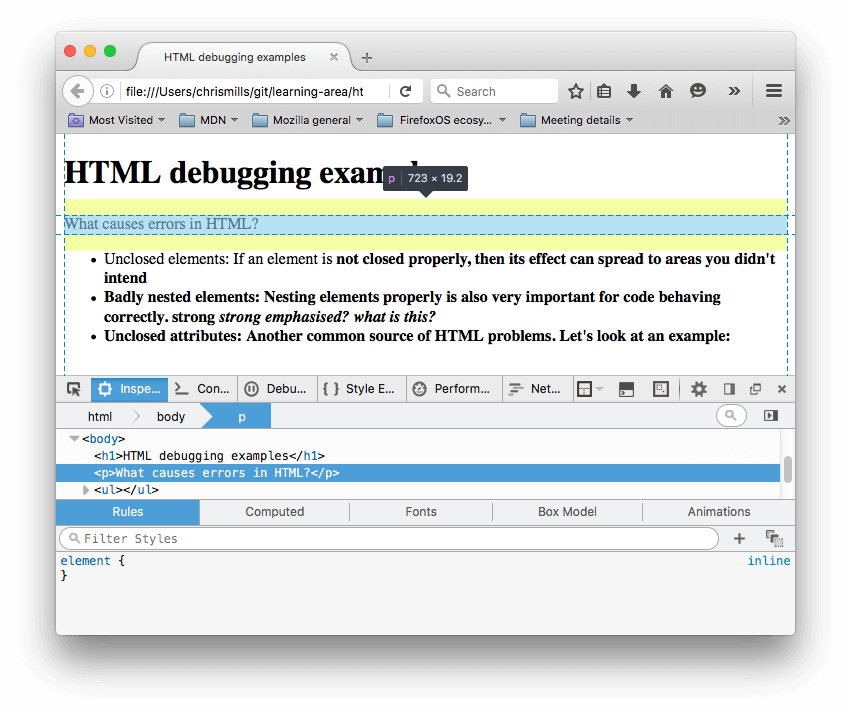
- 使用开发者模式下的审查器,可以非常清楚地看到浏览器尝试修补我们的代码错误(下面是火狐浏览器中的情况,其他浏览器也会进行修补)
- 段落和类表元素被加上了闭合标签。
- 第一个<strong>标签闭合的位置并不明确,因此浏览器用自己的<strong>标签将每一块分离的文本包括了进来,就在文档的底部。
- 浏览器像下面这样修补嵌套错误:
<strong>strong <em>strong emphasised?</em> </strong> <em> what is this?</em>
- 有错误属性的链接整个被删掉了。最后一个列表元素就像这样:
<li> <strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
HTML验证
看了上面的例子之后,你应该会希望自己的HTML格式正确。那么应该如何做呢?上面的例子都是一些非常小的错误,因此稍微浏览一下自己的代码就可以发现,但是如果是一个非常庞大、复杂的HTML文档呢?
最好的方法就是让你的HTML页面通过 Markup Validation Service — 由W3C创立并维护的, 这个网站紧跟定义 HTML, CSS, 和其他网络技术的具体内容. 这个网页将 HTML 文档作为输入,并运行 , 然后给你一个报告告诉你你的 HTML 有哪些错误.
为了确定需要验证的HTML,你可以输入一个指向该HTML页面的网址,或者上传一份HTML文件,或者直接输入一些HTML代码。
主动学习:验证一份HTML文档
让我们用sample document尝试一下:
- 在浏览器中打开 Markup Validation Service 。
- 点击或者激活 Validate by Direct Input 栏。
- 将整个示范文档的代码(不仅仅是body部分)复制粘贴到在Markup Validation Service中显示的巨大的文本框。
- 点击Check按钮。
然后就会出现一张列表,显示了文档中的错误或者其他信息。
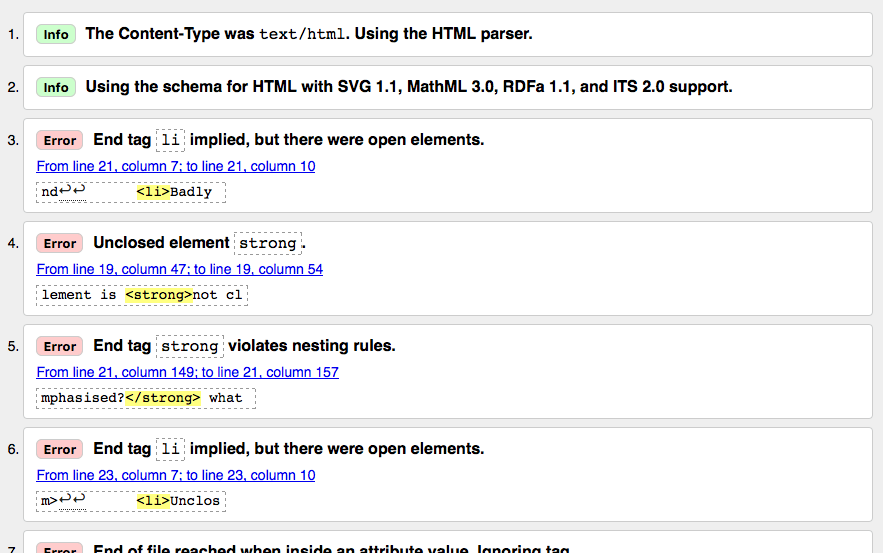
解析错误信息
展示在你眼前的错误信息列表可能会很有用,也可能并没有帮助。经过一点点练习你就会知道如何解析这些错误从而修复错误。让我们来浏览一下这些错误信息的含义。你会看到每一行都有一个数字和信息栏,来帮助你轻松定位错误。
- End tag
liimplied, but there were open elements (2 instances): These messages indicate that an element is open that should be closed. The ending tag is implied, but not actually there. The line/column information points to the first line after the line where the closing tag should really be, but this is a good enough clue to see what is up. - Unclosed element
strong: This is really easy to understand — a<strong>element is unclosed, and the line/column information points right to where it is. - End tag
strongviolates nesting rules: This points out the incorrectly nested elements, and the line/column information points out where it is. - End of file reached when inside an attribute value. Ignoring tag: This one is rather cryptic; it refers to the fact that there is an attribute value not properly formed somewhere, possibly near the end of the file because the end of the file appears inside the attribute value. The fact that the browser doesn't render the link should give us a good clue as to what element is at fault.
- End of file seen and there were open elements: This is a bit ambiguous, but basically refers to the fact there are open elements that need to be properly closed. The lines numbers point to the last few lines of the file, and this error message comes with a line of code that points out an example of an open element:
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Note: An attribute missing a closing quote mark can result in an open element, as the rest of the document is interpreted as the attribute's content.
- Unclosed element
ul: This is not very helpful, as the<ul>element is closed correctly. This error comes up because the<a>element is not closed, due to the missing closing quote mark.
、如果你不能一次弄懂所有的错误,别着急,你可以试试先修复那些你已经弄懂的错误,然后再申请验证,看看剩下的错误是哪些。有时候最先修复的错误可能让你摆脱了后面一系列的错误——因为一个小问题可能引发好几个错误,就像连锁反应。
当你所有的错误都修复之后,会得到下面的输出。

总结
这就是我们关于HTML debugging的介绍,这应该也会帮助你调试CSS, JavaScript, 或者你职业生涯的任何一种语言.。这也是HTML模块学习的最后一篇文章现在你可以用我们给你布置的任务来测试一下自己:下面的第一个链接。